
概要
前回の投稿で数千接続ぐらいならば分散処理はいらなそうと書いたが、そうはいってもきちんと処理できるように設計しておくべきだろうと考え直した。うまく分散処理の実装をしておけば、クラウドサービスを利用して面白そうな実験もできそうな気がしたので、ここは頑張りどころかなという考えを持つようになった(これはまた次回以降に考察する)。実装方法などと偉そうなタイトルを付けて説明していないのはいかがなものかという気もしてしまったため、今回はマルチテーブルトーナメントを分散処理する方法を考えてみよう。
分散処理システム
負荷の多い計算をする場合や非常に多くのネットワークアクセスがあるシステムでは分散処理システムという構成をとることが少なくない。分散処理を行う場合は計算処理やリクエストに対応した処理を行いレスポンスを返すなど、目的となる処理を実行するサーバ(子機)と、処理全体の進行を管理したり、タスクの振り分けを行うサーバ(親機)で役割を分けることが一般的である。このようなシステムの構成は昔はMaster/Slaveアーキテクチャと言われていた。現在ではSlaveという用語が差別的であるということで、Master(Controller)/Worker, Leader/Follower、あるいは、Parent/Subシステムと言われるらしい。
マルチテーブルトーナメントを分散処理システムで実装する場合も、基本的には親機と子機の役割を担うサーバを用意して、子機でクライアントとのソケット接続を抱え、親機が全体のゲーム進行の指示を行ったり、各種統計データを集計するといった役割を持つというのが通常の構成だろう。ポーカーは計算処理などCPUやメモリを食う処理がほとんどないため、子機に通信の役割だけを担わせて、ゲームの処理を親機に集約してしまうということも可能そうである。しかし、NPC(AI)を含めてゲームをプレイするような場合は、AIの行動決定アルゴリズム(モンテカルロシミュレーション)などを実行する必要があるため、相応に計算コストがかかる場合もあると考えられる。そのため、以下では個々のテーブルにおけるゲーム進行の管理は子機で行い、親機はMTT全体の進行管理のみを行うものと仮定して、分散処理の仕組みを考察しよう。
マルチテーブルトーナメントは以下のフェーズに分けることができるため、各フェーズにおける親機と子機の処理について考察していこう。
- 参加者募集期間(ゲーム開始前)
- 参加者募集期間(ゲーム開始後)
- 募集締め切り後
- ゲーム終了時
参加者募集期間(ゲーム開始前)
ゲーム開始前は参加者の募集を受け付けるのみであり、ほとんど処理がない。しかし、参加者に開始時のメッセージや情報を伝達する必要があるため、ソケット接続を保持しておく必要がある。通信を行わないとはいえ、接続を保持する必要があるため、この時点から接続先の分散を図っておく必要があるだろう。子機にソケット接続を分散する方法としては以下のような2通りの考え方があると推測できる。大きな差は無いように感じるので実装しやすい方法で実装すればよいだろう。
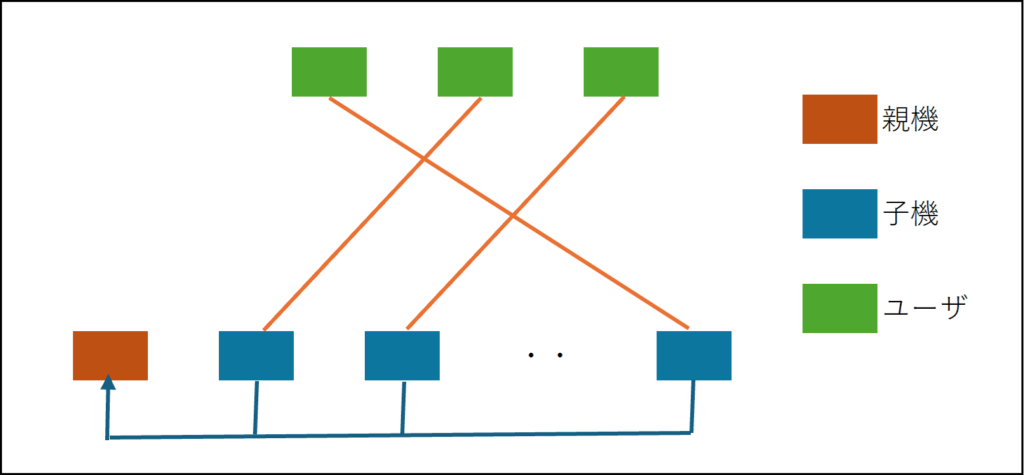
最初の方法は、クライアントは親機にREST APIなどで参加通知を行い、そのレスポンスとして接続先のサーバのIPアドレスを受け取って子機にソケット接続するという方法である。例えば、Table Balancingのアルゴリズムで同じテーブルになったプレイヤーは同じサーバに接続するように親機の方で接続先をコントロールするといった方法を考えることができるだろう。
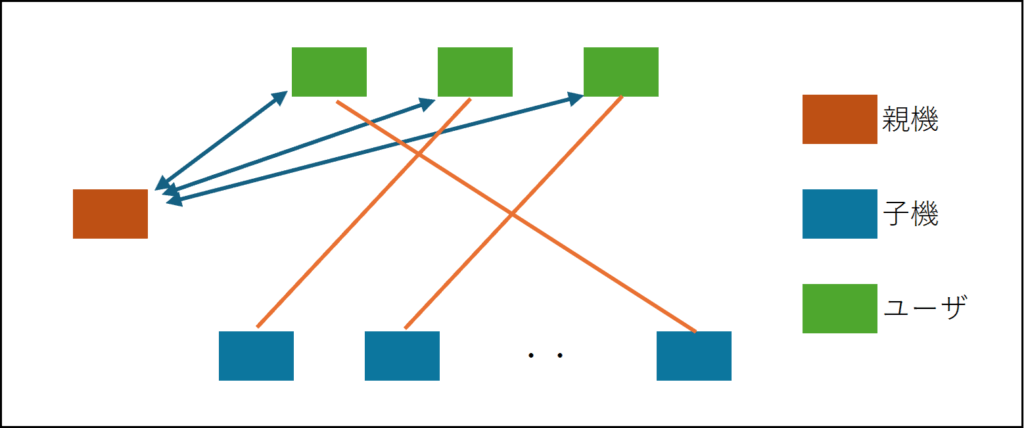
もう一つの方法は、クライアントはUser IDやIPアドレスに応じて、ランダムに子機にソケット接続を行い、参加通知を行う方法である(接続先の子機の割り当てはロードバランサーを用いてもよい)。参加通知を受け取った子機はサーバ間通信(バックプレーン)を使って親機に参加者の情報を転送することで情報を親機に集約する。
いずれの方法においても、最終的には親機が参加者の情報を集約的に保持しており、クライアントはいずれかの子機に分散してソケット接続しているという状態になるだろう。前者は親機が子機の情報をあらかじめ保有している必要があるため、決まった台数のサーバをレンタルしてサービスを構築する場合などに有効な方法と言えるかもしれない。子機についてクラウドサービスなどを利用して自動的にスケールしたい場合、子機はステートレスに設計(ユーザがどの子機に接続するかを制御できないため、子機に固有の情報やデータを持たないように設計)する必要があるため、選択肢は後者以外ないことに注意する必要がある。後者の方が洗練されている方法と思われるが、おそらくどちらの方法でも問題が生じることは無いように思われる。
ちなみに、Google Geminiに質問していたら、前者をステートフルセット戦略、後者をルーティングヘッダー戦略という名称を付けていた。Googleのクラウドサービス (Google Kubernetes Engine) を使う場合は後者の戦略がおすすめだということだった。反対に、ChatGPTはどちらかと言えば、前者の方法をお薦めしていて、後者の方法はRedisなどバックプレーンの負荷が重くなってボトルネックになるのではないかということだった。処理負荷に応じたオートスケールみたいな機能が欲しい場合は後者、ある程度処理負荷が見積もれる場合は前者の方法(子機がステートを管理する方法)でなるべく通信量を抑えた方がいいのかもしれない。
参加者募集期間(ゲーム開始後)
マルチテーブルトーナメントはゲーム開始後も一定の時間の間、追加の参加者を受け付けたり、短時間で敗北してしまったプレイヤーの再エントリーを受け付けることが一般的である。この期間は前節の参加者の受付処理とゲームの進行処理を並行して処理する必要がある。参加者の受付処理は前節と同様の方法で実行すればよいだが、参加者は最初は着席するテーブルが無い待機者リストに入れておいて、Table Rebalancingの処理でテーブルを割り当てるようにする。
ゲームの進行処理は基本的に前回の投稿で述べたとおりであるが、個々のテーブルのゲーム進行や結果は子機が保持しているので、親機と子機で情報を共有する必要がある。情報共有のタイミングは1ゲーム終了時で、各プレイヤーのスタックの変化量や脱落(スタックが0になったプレイヤーー)、テーブルの人数などを親機に通知する。
これも考え方は2通りで、サーバ間のメッセージングミドルウェアをバックプレーンとして利用できる場合は、子機から親機に各テーブルのゲーム終了時のデータを送信して、代わりに親機からMTT全体の統計情報のデータ(各プレイヤーの順位や残り人数、平均チップ数など)を受け取ればよいだろう。バックプレーンを用意していない場合は、この処理はREST APIで実行することもできそうである。単純に、親機に”https://xxx.xxx.xxx.xxx:yyyy/api_name”みたいな受け口を用意して、子機からパラメータとしてゲーム終了時のデータを引き渡し、APIのレスポンスとしてMTT全体の統計情報のデータと次のゲームの指示(そのまま開始する、待機リストから追加の参加者を追加、テーブルを解散など)を受け取ることで処理を実行できる。前節の実装方法で、REST APIによる方法を選択している場合は後者の実装方法が容易であるかもしれない。
サーバ間通信もソケット接続で対応すればよいのではないかと思うかもしれないが、サーバ間はネットワーク的に疎結合にしておきたいらしく、ソケット接続のような同期接続は一般的には使われないらしい。すべてのサーバが一気にクラッシュするというリスクを回避するためであるようである。子機が情報をデータベースに書き込んで、親機が定期的にデータを監視(ポーリング)するという方法もありそうだが、データベースのポーリングは負荷が重い処理であるため、極力避けた方が良いだろう。まあ、最後の手段としてデータベースのポーリングを選択するという開発者も結構いそうという偏見を筆者は持っているけど・・・
募集締め切り後、ゲーム終了時
募集締め切り後はゲームの進行処理のみを実行すればよい。テーブルが減ってくるとサーバを跨いだテーブルの再構成が発生するようになるので、これは旧子機切断+新子機再接続でクライアントと子機の接続を移動するようにすればよいだろう。待機状態のプレイヤーは旧子機に接続を残しておいて、親機からの移動指示を待つという形式になる。
クラウドサービスなどで自動スケールする場合は、再接続によるサーバ移動は難しいため、バックプレーンを使ってユーザとのメッセージを転送することで複数のサーバに接続しているユーザ同士でゲームを進行することができる。例えば、ユーザが異なるサーバにあるテーブルにアクションのメッセージを通知する場合はユーザ -> 接続しているサーバ -> テーブルの情報があるサーバ、となるし、反対にテーブルの情報があるサーバからユーザにメッセージを送る場合は反対の経路で通信することになる。
最後の1人を残して全員が脱落するとゲーム終了になる。ゲーム終了時は子機に終了通知を行い、ゲーム進行を行っていたスレッドなどは終了処理をする。ランキングデータなどデータベースに保存が必要なデータは親機がデータベースに保存する。
障害発生の対応
ここまではすべての処理が障害なく処理できる場合を想定したが、現実にはソケット接続が切れたり、子機が落ちてしまうという事態が発生する場合もあるだろう。親機が落ちた場合はどうしようもないのでここでは考察しないが、この2つのケースについてリカバリ策を考えよう。
最初に、単純にクライアントと子機のソケット接続が切れた場合は再接続をすればよいだろう。親機はそのユーザがどの子機に接続していたかの情報を持っているので、参加申請と同様の手続きで子機に再接続することができる。この場合、
- 接続が切れている間のゲーム進行をどうするか
- 一定時間以上再接続が無い場合どうするか
の処理を決める必要がある。1.はCheck or Foldで進行すればよいだろう。2.はデッドラインを決めて一定時間以上再接続が無い場合は退場扱いにするとした方が良いだろう。トーナメントではCheck or Foldしかしないプレイヤーは意外に長く生き残ってしまう上に、他のプレイヤーから見るとストレスを感じる邪魔なプレイヤーに見えてしまうため、短い時間(1~3分程度)で退場させた方が良いように思う。
子機が1台丸ごと落ちた場合であるが、これも基本的にはソケット接続が切れた場合同じ処理になるだろう。ただし、ゲームの進行を行うことができないため、親機の方で落ちた子機に接続していたプレイヤーは待機者リストに入れて、再接続があった場合はTable Rebalancingの処理で別の子機の新しいテーブルを割り当てるということになる。
以上で一通りの処理を実行できるだろうか・・・。複雑な処理に見えるし、実際に実装してテストしてみないと処理の不足があるかわからない部分もあるので、最初から完璧な仕様の記述は難しい気がする。実際に実装してみて、こうだったみたいな内容があれば後日追記するようにしたい。
結局どっちで実装する?
一応、筆者のゲームではGoogle Cloudを使って、Kubernetesで分散する方法で挑戦したいと考えている。必要な時に必要な分だけリソースを使える方が都合が良さそうであるからである(短い時間だけ多くのリソースを使うような実験をしてみたいため)。レンタルサーバの単価の安さ(同じスペックのマシンで値段がクラウドサービスの約半分ぐらいに見える)とオートスケールで必要な分だけを利用してコストを支払う方法でどちらの方がお得かという判断になるのかもしれない。技術的にはサーバのロジックをステートレスにしないといけないということで、これは筆者はやったことがないのであるが、まあせっかく作るので挑戦してみようかなと思った次第である。

